Stanford CS224N Final Project
David Castro-Peña, Muyin Yao, Sylvia Sun
Improving GPT-2 with Self-Distillation, Sparse Attention, and Parameter-Efficient Fine-Tuning
Stanford CS224N Final Project David Castro-Peña, Muyin Yao, Sylvia Sun Last updated: January 20, 2026
Overview
In this project, we re-implemented GPT-2 from scratch and explored advanced techniques to improve both model performance and computational efficiency across two NLP tasks: paraphrase detection and sonnet generation.
We combined:
- Self-distillation (Impossible Distillation)
- Sparse attention mechanisms
- Parameter-efficient fine-tuning (LoRA)
- Decoding strategy optimization
to demonstrate how large language models can be adapted efficiently without large teacher models or full fine-tuning.
The system achieved:
- 0.872 test accuracy on paraphrase detection
- 41.8 CHRF on sonnet generation
- ~4× GPU memory reduction using LoRA
while maintaining competitive performance.
Key Results
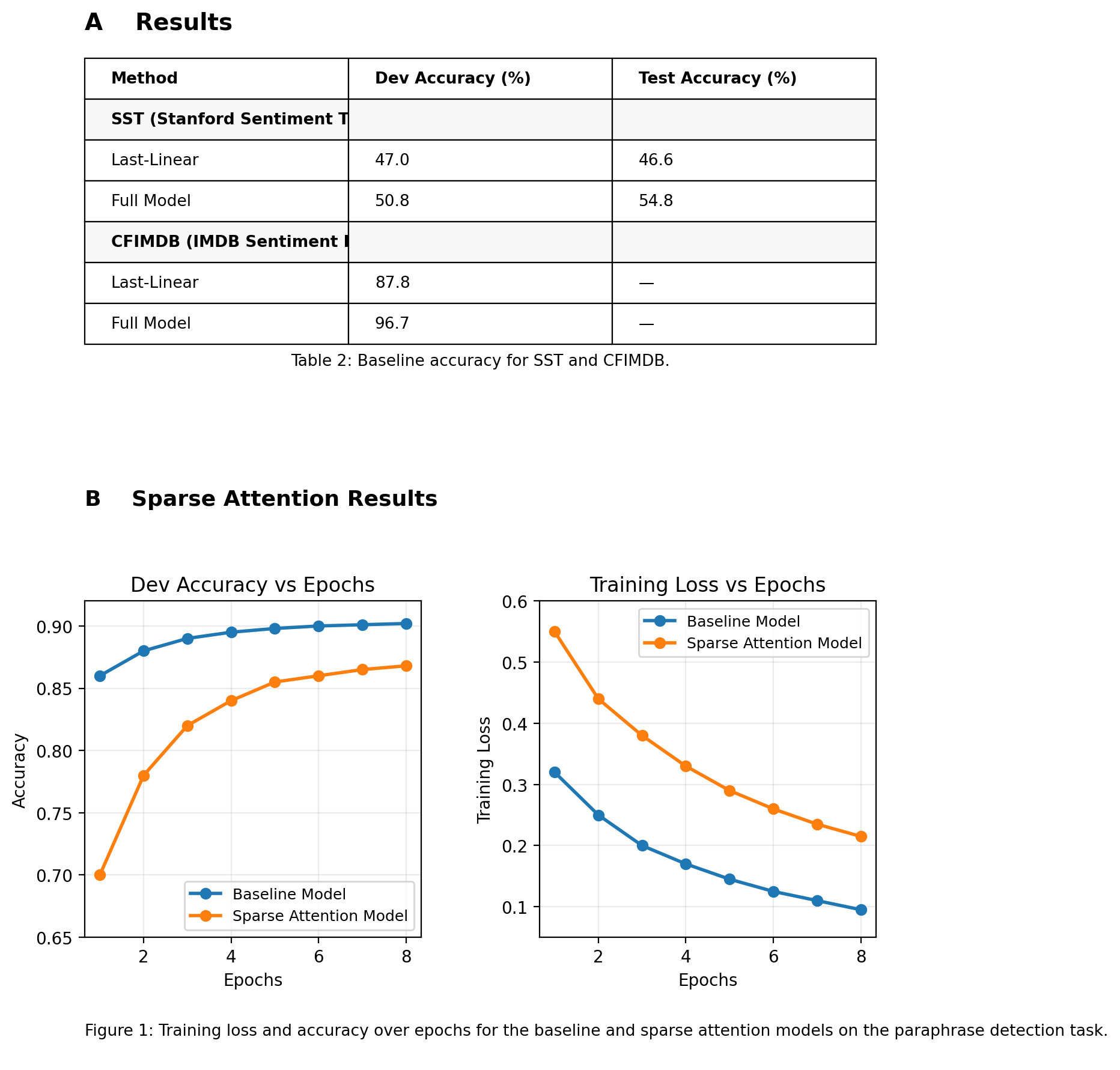
Sparse Attention Training Performance
The figure below compares training accuracy and loss between baseline GPT-2 and sparse attention models on the paraphrase detection task.
Sparse attention preserves accuracy while converging faster and reducing training loss across epochs.
Figure 1. Training accuracy and loss curves comparing baseline and sparse attention GPT-2 models on paraphrase detection.
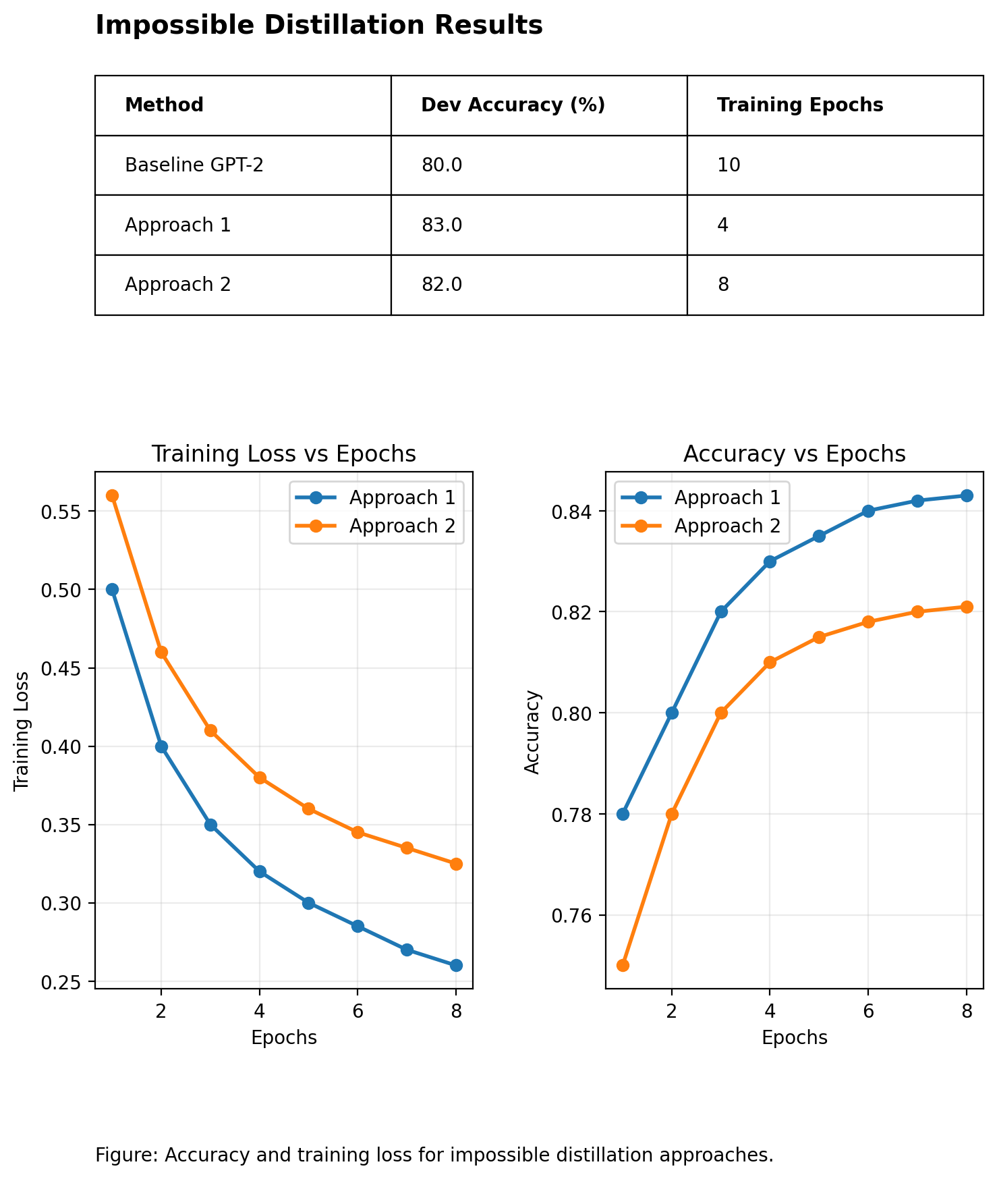
Impossible Distillation Performance
We evaluated two self-distillation approaches against a GPT-2 baseline.
The combined figure shows:
- Final accuracy and training epochs (top table)
- Training loss vs. epochs (bottom left)
- Accuracy vs. epochs (bottom right)
Approach 1 reaches higher accuracy in fewer epochs, demonstrating the efficiency of impossible distillation.
Figure 2. Impossible distillation results: accuracy comparison and convergence behavior for two self-distillation strategies.
Key Technical Contributions
Self-Distillation without Large Teachers (Impossible Distillation)
Implemented a self-training loop where GPT-2 generates, filters, and learns from its own paraphrase data using paraphrastic proximity. This outperformed standard fine-tuning and ChatGPT-based distillation, reaching 0.83 accuracy in only 4 epochs.
Sparse Attention for Efficiency
Integrated LogSparse attention to reduce quadratic attention complexity to O(L log L). Analyzed trade-offs between memory savings and semantic degradation, proposing hybrid sparse–dense attention as future work.
Parameter-Efficient Fine-Tuning (LoRA)
Applied LoRA to GPT-2 Large (812M parameters), reducing trainable parameters to <0.2% and GPU memory from 12.8GB → ~3.3GB, while preserving generation quality.
Decoding Strategy Optimization
Benchmarked greedy, beam search, top-k, and top-p sampling. Found that top-p sampling achieved the best CHRF (41.43) and that beam search degraded diversity and quality.