Demo
Note: The demo video includes an earlier collaborative version of the project.
All architecture, features, and updates described below reflect my independent work as of January 20, 2026.
PolicyChat — An AI Copilot for Policymakers 🤖📄⚖️
Last updated: January 20, 2026
PolicyChat is an AI-powered research assistant for policymakers, analysts, and researchers to discover, evaluate, and synthesize high-quality academic evidence for public policy decisions.
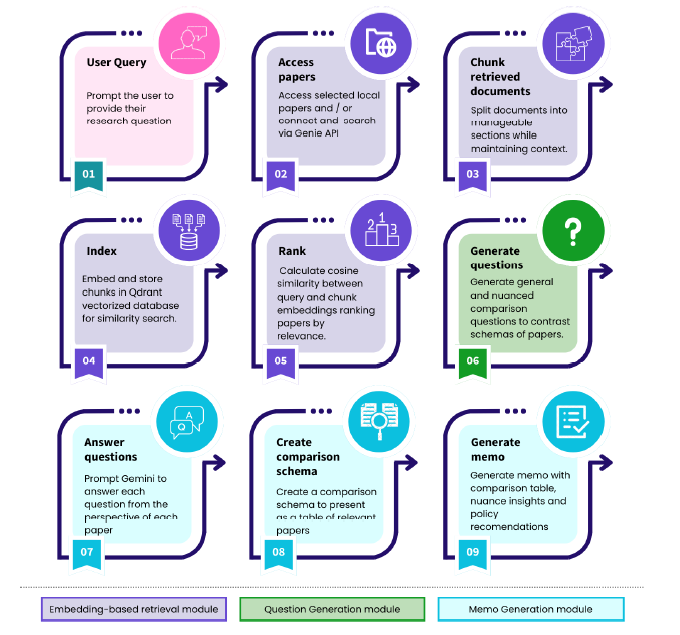
Unlike generic chatbots or simple RAG systems, PolicyChat implements a structured, evidence-aware research pipeline that prioritizes causal credibility, cross-study reasoning, and transparent synthesis.
It blends ideas from:
- Retrieval-Augmented Generation (RAG)
- Tool-using LLM agents
- Evidence-quality ranking and causal inference heuristics
- Multi-document question answering and synthesis
The system retrieves papers from multiple academic sources, grades evidence quality, generates comparative questions across studies, and synthesizes findings into structured policy memos rather than chat responses.
✨ What Makes PolicyChat Different
1. Evidence-Quality–Aware Retrieval (Core Innovation)
Instead of ranking papers only by semantic similarity, PolicyChat scores each study with an Evidence Quality Rating (EQR) based on:
- Methodological rigor (RCT, quasi-experimental, observational, etc.)
- Data quality and measurement
- Context match (population, geography, policy domain)
- Recency and policy relevance
- Venue credibility and scholarly impact
- Transparency and reproducibility
This allows the system to prioritize high-credibility causal evidence over weak or irrelevant sources.
2. Comparative Question Generation
Rather than summarizing papers independently, PolicyChat:
- Generates a shared comparison schema (mechanisms, outcomes, heterogeneity, limitations)
- Asks every paper the same structured questions
- Filters out papers that cannot answer the schema
This enables true cross-paper reasoning, not isolated summaries.
3. Multi-Source Academic Retrieval
PolicyChat integrates multiple scholarly metadata endpoints:
- Semantic Scholar
- OpenAlex
- Policy working paper sources (where available)
Results are deduplicated, ranked, and filtered before being passed to the LLM, with full provenance tracking.
4. Policy-Focused Synthesis
The final output is a policy memo, not a chat answer:
- Ranked evidence tables
- Comparative findings across studies
- Evidence-weighted recommendations
- Explicit sourcing and traceability
Designed for analyst and research workflows, not casual browsing.
🧠 Architecture (High-Level)
PolicyChat follows an agentic research pipeline, where each layer is an autonomous reasoning module with explicit inputs, outputs, and failure modes.
Layer 1 — Situation & Context Builder (Planned)
A planned "World Model" layer will ground retrieval in the current policy environment by modeling:
- Jurisdiction and population
- Existing programs and institutions
- Baseline indicators and constraints
This will enable context-aware retrieval and constraint-aware recommendations.
Layer 2 — Evidence Retrieval & Ranking
Multi-agent RAG layer with:
- Query Planner Agent for semantic expansion and decomposition
- Parallel multi-source retrievers
- Evidence Quality Rater Agent (EQR scoring + tiering)
Only top-tier evidence survives downstream.
Layer 3 — Comparative Reasoner
Schema-driven multi-document QA:
- Automatic question induction
- Per-paper constrained answering
- Cross-study alignment and filtering
Implements structured multi-document reasoning rather than free-form summarization.
Layer 4 — Policy Synthesizer
Retrieval-grounded long-form generation:
- Evidence quality summaries
- Ranked top evidence tables
- Comparative findings
- Mechanism-grounded recommendations
The synthesizer is constrained to retrieved evidence and explicitly tracks gaps and warnings.
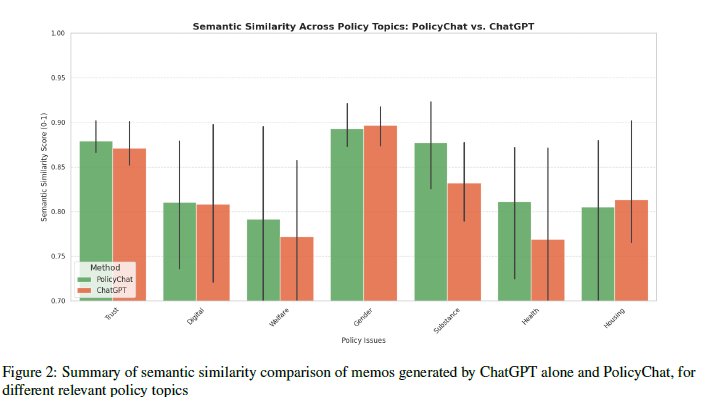
✨ Why This Matters (vs. ChatGPT / Standard RAG)
PolicyChat introduces capabilities that generic chat systems lack:
- Tool-using academic retrieval across multiple APIs
- Causal-aware ranking and tiered evidence gating
- Schema-driven cross-document reasoning
- Evidence-constrained synthesis
- Fully transparent and auditable agent logs
This makes the system suitable for policy, research, and governance workflows where credibility and traceability matter.
⚠️ Current Limitation
The system does not yet include a full Situation / World Model layer.
Future work will add institutional and contextual grounding before retrieval.
🚀 Running Locally
python3 -m venv myenv
source myenv/bin/activate
pip install -r requirements.txt
# Start Qdrant
docker run -d --name qdrant -p 6333:6333 qdrant/qdrant
docker start qdrant
# Run app
streamlit run ux.py